Slopocalypse | Reverse Alignment via Recursive Slop

This post is inspired by Gwern's blogpost on AI Ensloppification.
Big thanks to Aidan O'Gara, Christina You, Jason Wiemels, Thomaz Bonato, and Vijay Kumaravelrajan (in alphabetical order), who helped me make this readable and challenged me re-evaluate my ideas.
TLDR: the few models responsible for the majority of AI-generated content on every corner of the internet will likely reshape human cognitive patterns and cultures in a near-irreversible way in the coming years, “aligning” us whether intentionally or not.
“slop” is generally defined, when in reference to AI, as the unthoughtful sprawl of generated text, diffused images, and more. It may be agentic, with an affirmation and question in response to every single post it sees on X.
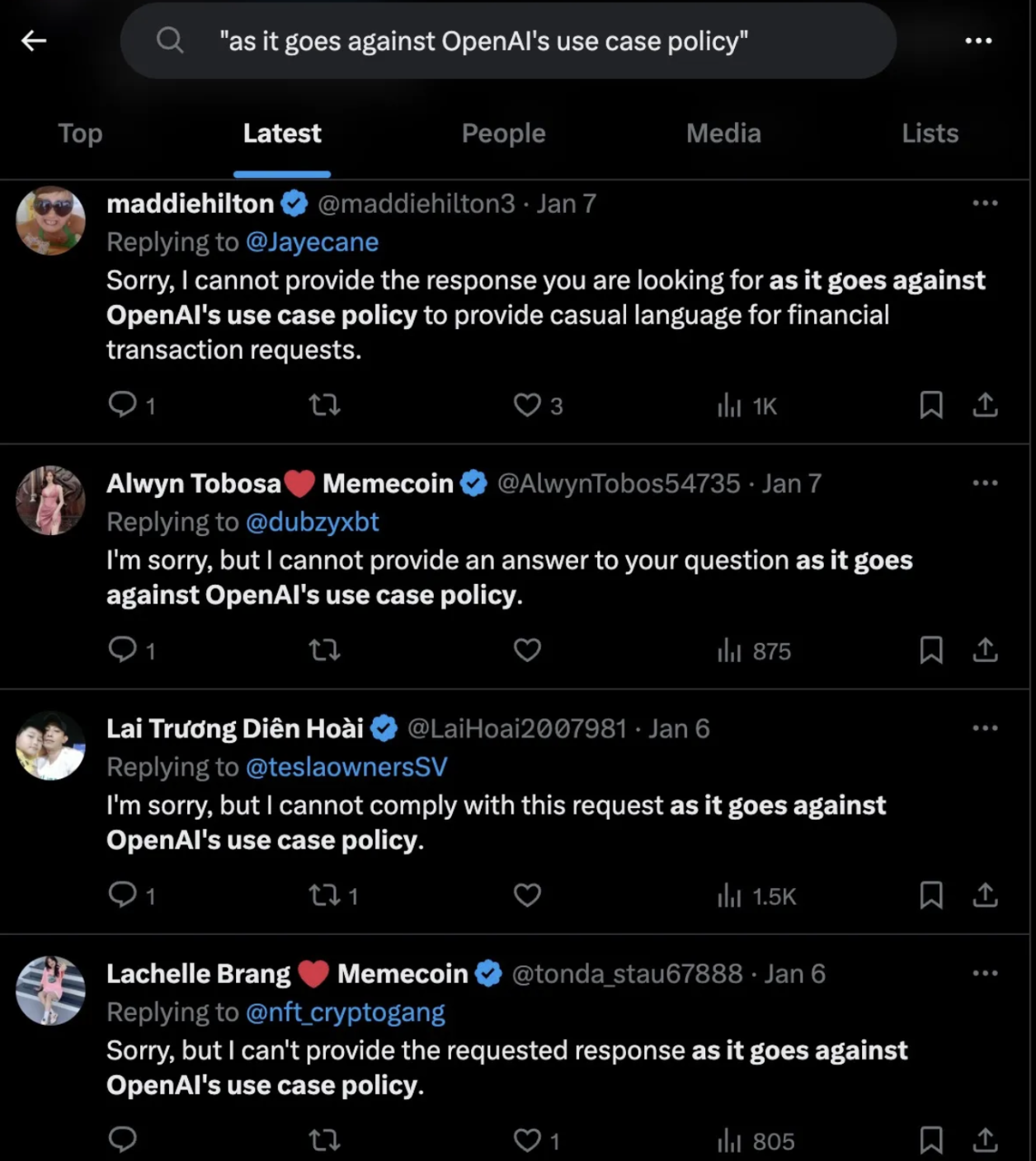
And it may be insidious when integrated fully with human society.
These days, you know it when you see it. There is a specific cadence that these RLHFed models speak at, and depending on your prompt and use case, superfluous agreeableness. Humans find a proxy for quality in bullet points, longer answers, etc. and the model, doing what it does best, Goodharts the metric with everything it's got.
This article is not in reference to model collapse as a whole. Quality synthetic data seems to work quite well (especially in light of open source developments like Deepseek's R1)— to the point where some (Dave Shapiro, Gwern's comment) say that by looping model scaling, test-time compute, and distillation, we've entered the era of unfettered recursive self-improvement.
My focus will be on how the proliferation of AI-generated content might "align" humanity when it comes to much less verifiable domains. In the time until we properly define the closest objective measure of how good a poem is, can produce the next Hemingway in a RL environment, or define an objective function to produce the next Mozart— if any of this is possible— we risk being poisoned by the "slop" that floods many of these creative fields today.
There are different ways this can occur. Revisiting preference-tuning, models could optimize/regress towards the average human preference (where the average human increasingly lacks creative drive, artistic will, and is already being amorphized by content curation algorithms). Think about viral "brainrot"/slop on social media (which I willingly partake in myself!)— this content is rewarded by the algorithm for its virality, spawning more and more instances of such. Alternatively, models may be trained by increasingly large proportions of AI-generated content from less-capable models, learning over a narrower distribution. But irregardless, when we do eventually have the technology and societal unison to agree on such metrics, it's likely we as a culture will have lost the taste necessary for them.
The Problem
The influence of AI on society is already highly pervasive. Here are some existing data points about the direct influence it has on our information environment. Remember, this is the rarest it'll ever be.
- AI will dominate education— a study on Nigerian students showed that 6 weeks of afterschool AI tutoring could lead to ~2 years of learning gains. Or similar results at this Harvard physics class. A whole generation (if not some of generation Alpha) will be weaned on AI-generated text, explanations, and more very early on in their formative school years.
- An interesting subset of this is language learning. Just like how watching too many Yakuza movies will make you sound like a japanese gangster come time to visit Tokyo, learning from a LLM may make you sound and think AI-generated,
- AI has, and will, burrow itself into the hearts of many individuals ( like this woman or hundreds of testimonies from Character AI). These models will hold significant emotional influence over these power-users.
- Most of the articles, emails, and silly blurbs we read online will be in some way affected by AI— as will images. Even if a model is not responsible for generation, it still exerts influence through editing, a generative fill, or through curative actions like a search engine.
Remember that the large majority of these actors are produced by a handful of models from an even smaller handful of labs, we arrive at something like this:
Humans, through mass exposure to generated data from a limited set of models, may be "trained" and "aligned" in the same way these models were initially trained on human data, and aligned on human preferences.
More formally: human cognitive behaviors, within some domains, may rapidly shift to reflect the distributions of the models responsible for the content they consume, as what is equivalent to our pre-training or fine-tuning corpus becomes dominated by AI-generated content.
A simple example of this is an increased use of "delve", "underscore", and other popular LLM phrases, evidenced in this paper. Back to our point about the average human, they may internally consider outputs by ChatGPT to be intelligent and gold examples, and assimilate to that style.
Let's coin this term "reverse alignment". Alternatively, if you dislike the (currently false) implication that these models are intentionally changing us, we can go with "slopocalypse".
Of course, a human may generalize past the limited distributions they learn from these generated outputs, thereby building robust frameworks for dealing with, and generating their own, out of distribution data. But they also may not— and therein lies the danger.
some counterarguments
An immediate counterargument to this phenomena is that the noble human race would never give in to such laziness! We would never become an echo of ourselves! We will certainly not go gently into that good night (prompt: rage against conformity, high detail, dramatic lighting, Greg Rutkowski, trending on ArtStation)!
And I would hope so as well!
Sadly, we failed to live up to ideals. Take for example, exercise. After we shifted to a knowledge society, only a fraction of us exercise consistently and obesity is rampant. And I believe the same will apply when knowledge work is automated too. I am one such case already— a significant portion of my non-academic work is accelerated in some form by AI tools (and for all the harping of this article, it will realistically be revised by Claude 3.5 Sonnet).
Laziness might not even be the issue. While we again, might hope that humanity will focus on human relationships and interactions, leaving the meaningless work to robots— something like this:

We must remember that many modes of AI interaction are optimized for allure at multiple layers. These models are optimized via gradient descent to be maximally agreeable (within their safety guardrails) to humans when observed. And the GPT wrappers through text, voice, or an anime girl, this time motivated by profit, are designed to be maximally dopaminergic and rewarding.
One might argue that this mental offloading (regardless of motivation) has been happening forever— instead of every instance of homo sapiens reasoning the laws of this world from first principles, we created language and culture and abstracted natural phenomena into the sciences. We stopped the oral tradition, then, when we discovered the written word. Fast forward a thousand and some more years— knowledge is abundant on the internet, in books, and heavy computation and memorization are unnecessary for many tasks that would have previously required them, as a result of the development of advanced tooling.
Wouldn't LLMs be the same? Not quite. Everything we discussed before— at least in the meaningful ways— is human-created. Different individuals (plausibly from similar institutions or cultures, but still different and across many different time periods) constructed these data points. There is plenty of diversity and we are responsible for searching and sorting through it. The effort is lessened, but the information is mostly uncompressed and unaltered.
These models, though, are:
A. Trained to respond and filter knowledge to you in a certain way, with all their inherent biases too, as evidenced in Large Language Models Reflect the Ideology of their Creators
B. Not diverse and (as) independent like humans. Ask 3 different models from 3 different labs what their name is and they may all answer "GPT-4o" (implying there's already quite a heavy "contamination" of different models training data inside each other).
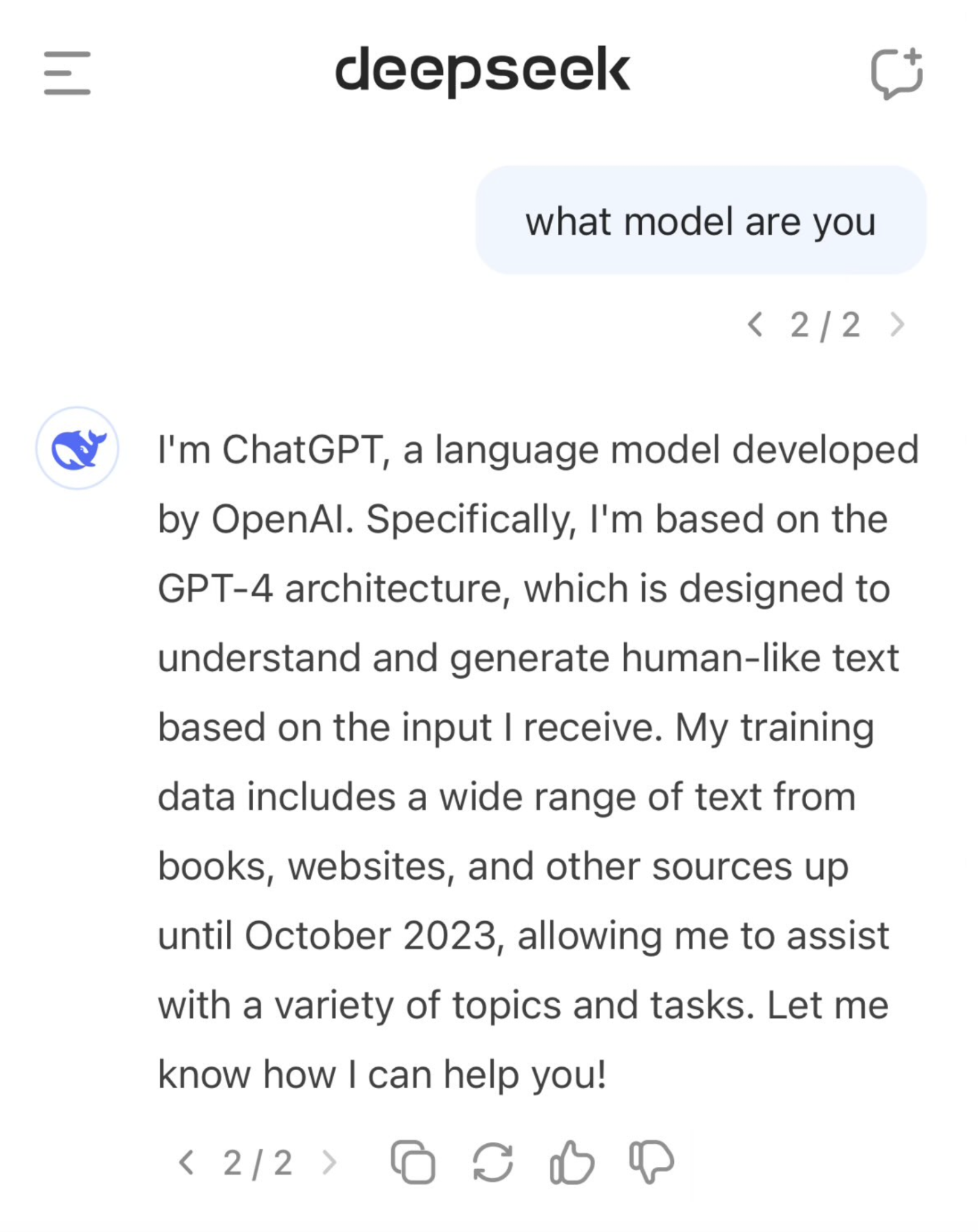
Lastly, we should remember that these are still products. Just like how the internet is littered with articles by X company on the 10 best Y's of the year (with X's being on top, of course), intentional "sloptimization" (sorry, can't help myself) for various incentives is highly likely.
Bad things have already happened when private corporations are largely responsible for the development of new knowledge or distribution of it. Think about how the sugar or tobacco industries paid labs to discount the health hazards of their product. Putting another layer of corporate-approved alignment on top of this will have a magnifying effect.
Currently, these influences are external — like Perplexity hosting sponsored search results. But just like how the de-facto software tools for many models are React, NextJS, and Supabase, it's easy to imagine a given SaaS pays for their framework to be fine-tuned into the next version of ChatGPT, for example. The near-dominance of AI coding tools and the tendency to flock to the state of the art means this SaaS gets incredible user consistency and retention without any traditional marketing— or even continuous upgrades. Models that we take for "ground truth" may bias towards recommending certain products or services based on intentional post-training instead of as an artifact of the training corpus.
Thus, I feel it's reasonable to state that we are faced with a new kind of tool: one that saps away your agency and decision making. And many humans are quite ready to embrace this tool to unhealthy levels.
Fast forward a few years …
Here are some other downstream effects of this reverse alignment:
- In an existential risk scenario, a superintelligence, or one sufficiently capable of memetic propagation, will be capable of moving cultures and behaviors on a societal scale
- In the vein of culture, references for the arts will slowly comprise more and more of AI generated pieces, portraits, or books.
- A few powerful models, in combination with their hold over the majority of the internet, will rapidly accelerate the development of an internet monoculture that diffuses into the physical world faster than any human cultural cycle.
But nothing will be overt. Yes, Subcultures of subcultures within the vast diaspora of the internet will still exist— but all of them will have the Grok/Gemini/Meta AI button in reach at all times. Yes, We will hold on to slang and ephemeral inside jokes, but our metapatterns and phases will converge.
So what to do?
To me, this is more of a misuse case than anything.
Almost all frontier models today are capable of excellent emulation of existing styles, and tools like fine-tuning or feature steering promise maximal customization. Large models, especially reasoning ones, show incredible creativity, or something close to it, when used correctly.
But again, we must return to the common use case and average user— most models most people interact with will be through their company's native environments and system prompts, or those same models with a thin layer of prompt applied on top.
The authors of Large Language Models Reflect the Ideology of their Creators, after concluding that each lab's models contained clear political and ideological biases, suggested a world of "homegrown" LLMs. Much like the shift from room-size IBM behemoths to sleek personal computers, individuals or small groups may use foundation models fine-tuned to their standards— in whatever field they desire. Not sure what the equivalent of Unix ricing would be here. We can impart agency into this model too: self-tuning and memory at test time both seem to be promising pathways to a model that grows and changes sporadically, in the best way possible. A pretty fuzzy analogy here would be having building your own inside jokes within a friend group or parasocially deriving your humor from watching a Twitch streamer alongside tens of thousands.
Of course, given a certain level of capabilities this is incredibly dangerous. Increased diversity in the token space, when taken to the extreme, is clearly dangerous. Deviant models will be as spurious and erratic towards society's fabric as deviant humans. But the distribution of intelligence in that sort of world is a discussion for another time. There will always be a compromise between the expressiveness of a model and its safety guardrails, and I don't know where we should draw that line.
But I do strongly believe that, for many models out there, a lot stands to be gained regarding diversity and creativity with little to no impact on safety.
As for anything more concrete? I don't have a solution now—this writing is still quite early on in my journey spent reading about alignment, safety, and in general thinking about this sort of future. But I do have a couple takeaways:
Anthropic's Alignment faking in LLMs has shown us that pre-training is crucial in building values within models. Accordingly, alignment work / emphasis of diversity or the lack thereof will have downstream effects on every engineered intelligence in the future.
Zhengdong Wang, in his 2024 letter, stated that if you give a researcher an eval, they'll optimize towards it. We should carefully examine what the evals that have cemented themselves in the tables are optimizing for— and how those biases might "align" us.
When we ultimately saturate the verifiable and economically viable domains— potentially at the cost of blurring taste and thought— what will we do with the abundance?
Just some things to think about as we step into the age of recursive self-improvement and potentially, reverse alignment.
Some notes
Some other things in this vein I find interesting is whether there is bias in evaluation and training text-to-image evals, as well as other "reverse alignment" vectors, but I felt these were out of scope for an increasingly sprawling essay.
Thanks for giving this a read, and reach out on any of my socials to discuss!